
| tb005 | システム変数_n, _Nの用法 |
Stataが用意しているシステム変数にどのようなものがあるかについてはマニュアル [U] 13.4 System variables の項をご参照ください。ここでは_nと_Nという2つのシステム変数について、その用例を紹介します。
| _n | indexing用のシステム変数 |
| _N | データセット内、またはグループ内のobservations総数 |
今、10件の観測データ(observations)を含むデータセットを新たに作成し、その中に1から10の番号を持つID変数を設定したいとします。Indexing用のシステム変数_nを使うとこの操作が簡単に行えます。
. set obs 10 *1
. generate id = _n *2
. list id
_nは先頭のobservationから順に1, 2, ...という値を取るため、その値を用いて変数idを生成してやれば、所定のID変数が生成できるわけです。
| *1 | set obsコマンドの仕様についてはマニュアルエントリ [R] set を参照ください。 |
| *2 | id = _n - 1 とすれば 0, 1, 2, ... というIDが生成できます。 |
_nも_Nもby prefixと併用された場合には、グループ単位の値を取ることになります。すなわち_nについて言うなら、グループが切り替わるごとにインデックス値は1にリセットされることになります。
ここではExampleデータセットcensus.dtaを用いた用例を紹介します。
. sysuse census.dta
このデータセットには米国における国勢調査データが州別に集計された形で記録されています。多くの変数が含まれていますが、ここでは変数regionの値を用いたグルーピングを考えることにします。regionは米国内における地域区分 − North East, North Central, South, West − を表し、それぞれ1, 2, 3, 4というコードで表現されています。今、それぞれのリージョンから人口(pop)の多い順に2州を抽出し、リスト出力をしたいとします。この操作はシステム変数_nを用いることにより簡単に行うことができます。
. gsort region -pop *3
. by region: generate flag = 1 if _n <= 2
. list state region pop if flag == 1, separator(2)
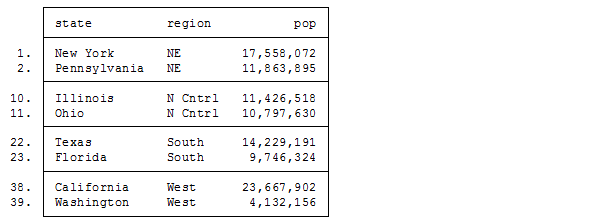
各リージョンごとに_nの値が1にリセットされる点がポイントです。
| *3 | メニュー操作の場合には Data > Sort と操作します。popに対しマイナスの符合が付いていますが、それは下降順ソートを意味するものです。詳細は [D] gsort を参照ください。 |
![]() ページへ戻る
ページへ戻る
| = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = |
© 2018 Math工房