| tb007 | 欠損値の扱い |
数値変数の場合、欠損値(missing values)は"."という形で表現されます。今、regressコマンド等を用いて回帰推定を行う際に、k個の説明変数x1, x2, ..., xkが設定されたとします。このとき、i番目のobservation(観測データ)の変数値xi1, xi2, ..., xikの中に1つでも欠損値が含まれていた場合、そのobservationは推定では使用されないことになります。このアプローチはcasewise deletion、あるいはlistwise
deletionと呼ばれます。
そのような意味で欠損値の存在は回帰推定の効率に少なからぬ影響を及ぼすわけですが、単なるデータ操作を行う上でも欠損値の扱いには注意が必要です。比較演算操作において欠損値は無限大の実数値としての扱いを受けることになるからです。
Exampleデータセットfullauto.dtaを用いて具体的な例を見て行くことにします。
. use http://www.stata-press.com/data/r15/fullauto.dta
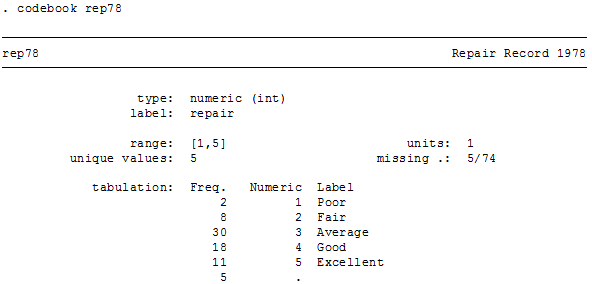
このデータセット中には1978年に米国で販売された74車種の情報が記録されているわけですが、ここで着目するのはrep78というカテゴリ変数です。これは1978年度の修理歴に基づき車の品質を1から5までの数値で5段階評価したものなのですが、次に示すように5車種については欠損値が含まれています。
. codebook rep78
今、評点が5の車種を抽出するのに等号(==)ではなく不等号(>=)を用いて操作を行ったとします。
. list make rep78 if rep78 >= 5

16車種が抽出できたわけですが、中の5車種のコードは欠損値である点に注意してください。ここで指定した条件式の形では無限大の値を持つ欠損値も拾われてしまうのです。欠損値を排除したい場合には、次のような条件設定とする必要があります。
. list make rep78 if rep78 >= 5 & rep78 < .

なお、欠損値の生じた理由等を区別するため、".a"から".z"までの拡張コードを併用することも可能です。いずれも無限大の数値として扱われます。
文字列データの場合には""が欠損値を意味することになります。
統計パッケージによっては別のコードが欠損値として用いられていることがあります。そのような場合には欠損値コードの変換操作が必要となるわけですが、それを支援するものとしてmvencode/mvdecodeというコマンドが用意されています。[D] mvencode (mwp-081) をご参照ください。
![]() ページへ戻る
ページへ戻る
| = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = = |
© 2018 Math工房